数据离散程度的度量
数据离散程度的度量相关课程
 数据离散程度的度量考点解析
数据离散程度的度量考点解析
 数据离散程度的度量介绍
数据离散程度的度量介绍
数据离散程度的度量(极差、方差、标准差和离散系数)
1、极差(Range)
一组数据的最大值与最小值之差,计算简便易于理解,未充分利用中间部分数据的信息,因而无法全面反映数据的离散程度。
![]()
2、方差(Variance)和标准差(Standard Variation):应用最广泛的离散程度度量指标。
方差是一组数据中每个数值与该组数据平均值离差平方和的平均,标准差为方差的平方根。两者利用了全部的样本数据信息,具有较高的灵敏度和全面性,数值越大表明数据中数值的分布越分散。
方差:
![]()
标准差:
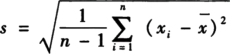
3、离散系数(Coefficient of Variation)
也称变异系数,度量数据离散程度的相对统计量,用于比较不同组数据的离散程度。消除了绝对数值和单位对于度量值的影响,反映不同组数据之间离散程度的差异。
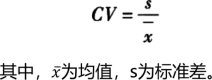

期货投资分析知识点:什么是极差

期货投资分析知识点:什么是方差

期货投资分析知识点:什么是离散系数
数据离散程度的度量考点试题
正确答案: B
答案解析: 数据的离散程度不仅取决于数据自身的变异性,还会受到数值大小和单位的影响。
正确答案: D
答案解析: 数据的离散程度不仅取决于数据自身的变异性,还会受到数值大小和单位的影响。因此在比较不同组数据之间的离散程度时,极差、方差和标准差并不是一个理想的指标。离散系数由于可以消除绝对数值和单位对于度量值的影响,可以更加真实地反映不同组数据之间离散程度的差异。
正确答案: B
答案解析: 数据的离散程度描述了一组数据中各数值远离数据中心值的程度。常见的离散程度度量指标主要有极差、方差、标准差和离散系数。(BC两项是数据集中趋势的度量指标)
大咖讲解:数据离散程度的度量


假设检验
假设检验✭
一、基本概念
假设检验——一种基于小概率原理结合反证法判断给出的命题在统计意义下是否成立的统计推断方法。
小概率原理——小概率事件在一次实验中几乎不可能发生,在假定原假设正确的情况下,如果一个小概率事件发生了,则可以认为原假设是错误的,进而拒绝原假设,接受备择假设。
基本思想——首先对研究总体的参数做出假设,再根据利用样本构造的统计量来检验该假设是否成立。
1、原假设与备择假设
(1)原假设(记为 H0)与备择假设(记为 H1)是需要证明或推翻的结论。一般把想要证明是错误的假设作为原假设,而将希望正确的假设作为备择假设。
原假设一般包含等号,比如≥、≤或=;备择假设一般包含不等号, 比如>、<或≠。
(2)类型
双尾假设和单尾假设(左尾假设和右尾假设)
举例:以总体均值 μ0 的假设检验为例
双尾假设:H0: μ=μ0,H1: μ≠μ0;
左尾假设:H0: μ≥μ0,H1: μ <μ0;
右尾假设:H0: μ≤μ0,H1: μ>μ0。
2、两类错误与显著性水平
(1)两类错误
第一类错误:原假设本来是正确的,却被拒绝了,也称为弃真错误或α错误;
第二类错误:原假设本来是不正确的,却没有被拒绝,也称为取伪错误,或β错误。
(2)显著性水平
在实际检验通常希望能尽量避免犯错误,通常优先控制犯第一类错误的概率不大于一个较小的值α,然后使β值尽可能小。
将犯第一类错误的概率α称为显著性水平,一般由研究者事先确定,是当原假设为真时拒绝原假设的概率,也是犯第一类错误的概率的最大值。
3、假设检验的步骤
①根据实际问题建立原假设和备择假设;
②根据总体情况选择适当的检验统计量;
③根据给定的显著性水平α,确定出临界值与拒绝域;
④利用样本计算出的检验统计量的值或者用P值进行决策。

参数估计
点估计
1、概念:
利用样本统计量的某个取值直接作为总体参数估计值的方法称为点估计。常用的点估计方法:矩估计法、 极大似然法、最小二乘法。
区间估计
(一)、概念
在点估计的基础上,构造置信区间对参数进行估计,由点估计值加减抽样误差得到区间估计,点估计值减去抽样误差构成区间估计的下限,点估计值加上抽样误差构成区间估计的上限。
抽样误差=zα/2 ×点估计的标准误差
或者:
抽样误差=tα/2 ×点估计的标准误差

抽样分布
正态分布(Normal Distribution)
又称高斯分布,应用最广泛的一种连续型分布。
正态分布的概率密度函数呈钟形分布,曲线关于 x=μ 对称,并在 x=μ 处达到最大值。曲线的陡峭程度由σ2决定:σ2越大,曲线越平坦; σ2越小,曲线越陡峭。当x趋近于无穷大(或无穷小)时,曲线无限接近于x轴。
标准正态分布:期望μ=0、标准差σ=1。
Φ(-x)=1 -Φ(x)
其中,Φ(x) 为标准正态分布的分布函数
二、χ2分布(卡方分布)
1、若有n个相互独立且服从标准正态分布的随机变量X1,X2,…,Xn ,则可利用这n个随机变量的平方和构成一新的随机变量,其卡方分布规律称为χ2分布(Chi-square Distribution)。参数 n 称为自由度,χ2分布特征由自由度决定。
2、随着自由度n的增大,卡方分布向正无穷方向延伸(均值n变大),分布曲线在形态上也会愈发平坦,即χ2分布的方差与自由度有正向关系。
3、χ2分布具有可加性。
则X+Y服从自由度为(n1+ n2)的χ2分布;同理,X-Y服从自由度为(n1-n2)的χ2分布。
若X~χ2(n1) 与Y~χ2(n2) 相互独立

描述性统计
数据集中趋势的度量(平均数、中位数和众数)
1.平均数(Average)
反映一组数据平均水平的统计指标,包括简单算术平均数、加权算术平均数和几何平均数。最常用的集中趋势度量指标,其优点是可利用所有数据的信息且计算相对简单,缺点是易受少数极端值和异常值的影响。
2、中位数(Median)
将一组数据按照从小到大的顺序排序后,处于该组数据中间位置的数值。不易受极端数值影响,当数据呈现出明显的偏态分布时具有较强的代表性。
3、众数(Mode)
一组数据中出现频次最多的数值。不易受到极端值的影响,但在数据量较小的情况下会失去代表性。

数据集中趋势的度量
数据集中趋势的度量(平均数、中位数和众数)
1.平均数(Average)
反映一组数据平均水平的统计指标,包括简单算术平均数、加权算术平均数和几何平均数。最常用的集中趋势度量指标,其优点是可利用所有数据的信息且计算相对简单,缺点是易受少数极端值和异常值的影响。
2、中位数(Median)
将一组数据按照从小到大的顺序排序后,处于该组数据中间位置的数值。不易受极端数值影响,当数据呈现出明显的偏态分布时具有较强的代表性。
3、众数(Mode)
一组数据中出现频次最多的数值。不易受到极端值的影响,但在数据量较小的情况下会失去代表性。

数据分布形状的度量
数据分布形状的度量(偏度、峰度)
1、偏度(Skewness)
也称偏态系数,度量一组数据分布的偏斜方向和偏斜程度。
2、峰度(Kurtosis)
又称峰态系数,度量一组数据分布的陡峭或者平坦程度。

数据的位次指标
数据的位次指标(四分位数、四分位差)
1、四分位数(Quartile)
将一组数据按照从小到大的顺序排序后,处于数据中25%和75%位次上的数值,这两个数值分别为下四分位数Ql和上四分位数Qu。先确定数据中数值的位次,然后根据位次得出相应数值。
Ql对应的位次:n+1/4;
Qu对应的位次3(n+1)/4;
注意:如四分位位次不是整数,则取该四分位位次前后的两个整数位次上数值的加权平均数作为该组数据的四分位数。使用的权重取决于两个整数位次与四分位位次之间的距离:整数位次与四分位位次距离与权重成反比。
2、四分位差(Quartile Deviation)
一组数据的上四分位数与下四分位数的差值:d = Qu -Ql
反映了一组数据中间50%数值的离散情况,数值越大表明该部分数据分布越不集中,离散程度越深。

箱线图
利用一组数据的最大值、上四分位数、中位数、下四分位数和最小值绘制而成的一种统计图。反映原始数据的分布特征,比较多组数据分布特征的差异。








拒绝盲目备考,加学习群领资料共同进步!












师资团队
-

免费听
王佳荣
金融圈达人
主讲:金融市场基础知识,期货基础知识,基金法律法规,中级金融
从事金融类考试培训多年,知名金融培训师、金融机构中层管理、清华大学出版社金融教材副主编、上海人才培训市场促进中心特聘讲师。人称金融类培训界的“一哥”。

免费听
孙婧
外汇分析师
主讲:期货法律法规,投资银行业务(保荐代表人),证券市场基本法律法规,中级法律法规与综合能力,初级法律法规与综合能力
曾就职于多家大型证券、期货公司,具有丰富的金融从业培训经验,外汇分析师,大学生金融交易大赛评委,同时拥有金融类多个从业资格。
-
免费听
李泽瑞
金融培训高级讲师
主讲:证券投资顾问业务,发布证券研究报告业务(证券分析师),初级个人贷款,中级个人贷款,期货投资分析
经济学硕士、金融培训高级讲师,李泽瑞老师从事金融类考证培训,教学经验丰富,出口成“段子”,是一个让学员欲罢不能的很有个人风格的老师,江湖学员称被讲课耽误的“德云社”编外弟子。
免费听
王佳荣
金融圈达人
主讲:金融市场基础知识,期货基础知识,基金法律法规,中级金融
从事金融类考试培训多年,知名金融培训师、金融机构中层管理、清华大学出版社金融教材副主编、上海人才培训市场促进中心特聘讲师。人称金融类培训界的“一哥”。

专业智能,高效提分
章节练习
章节专项突破
进入做题
精选试题
省时高效精选
进入做题
模拟考场
海量题免费做
进入做题
考前点题
高效锁分72小时
进入做题
每日一练
每天进步一点点
进入做题
历年真题
真题实战演练
进入做题
易错题
精选高频易错题
进入做题
模考大赛
同场闯关做题
进入做题

APP刷题神器
模考大赛
考点打卡
做题闯关

扫描二维码 下载233网校APP刷题
互动交流

微信扫码关注公众号
获取更多考试资料